Department Of Computer Science Engineering, Gov Engineering College Wayanad
The convergence of big data and cloud comput- ing offers numerous advantages, including scalability, cost- effectiveness, flexibility, collaboration, and accessibility. Cloud platforms allow for seamless resource scaling, eliminating the need for heavy infrastructure investments. Paying only for utilized resources reduces upfront expenses. Cloud-based solu- tions provide flexibility in storage and processing capabilities, allowing for tailored adjustments as organizational needs evolve. Collaboration is fostered, enabling data sharing and teamwork among diverse users and teams. Accessibility becomes universal, harnessing the potential of big data analytics from any location with an internet connection. However, challenges such as data security and privacy, latency issues, and the cost of long-term storage and complex analytics tasks in the cloud need to be addressed. Robust security measures, efficient data management strategies, and adherence to compliance standards are necessary to ensure the safe and effective utilization of big data within cloud environments.
With recent technological advancements, the amount of data available is increasing day by day. For example, sensor networks and social networking sites generate overwhelming flows of data. In other words, big data are produced from multiple sources in different formats at very high speeds.At present, big data represent an important research area. Big data are rapidly produced and are thus difficult to store, process, or manage using traditional software. Big data technologies are tools that are capable of storing meaningful information in different types of formats. For the purpose of meeting users requirements and analyzing and storing complex data, a number of analytical frameworks have been made available to aid users in analyzing complex structured and unstructured data. Several programs, models, technologies, hardware, and software have been proposed and designed to access the information from big data.The main objective of these technologies is to store reliable and accurate results for big data. In addition, big data require state-of-the-art technology to efficiently store and process large amounts of data within a limited run time. Three different types of big data platforms are interactive analysis tools, stream processing tools, and batch processing tools. Interactive analysis tools are used to process data in interactive environments and interact with real-time data. Apache Drill and Google’s Dremel are the frameworks for storing real-time data. Stream processing tools are used to store information in continuous flow. The main platforms for storing streaming information are S4 and Strom. Hadoop infrastructure is utilized to store information in batches. Big data techniques are involved in various disciplines, such as signal processing, statistics, visualization, social network analysis, neural networks, and data mining. What is Big Data? Big Data refers to extremely large and diverse collections of structured, unstructured, and semi-structured datasets that grow exponentially over time. These datasets are characterized by their immense volume, the velocity at which they are generated, and the variety of data types they encompass, rendering traditional data management systems insufficient for their storage, processing, and analysis. The rapid proliferation of data is driven by advancements in digital technologies, including connectivity, mobility, the Internet of Things (IoT), and artificial intelligence (AI). Consequently, organizations are increasingly leveraging specialized Big Data tools to process and analyze information at unprecedented speeds, enabling them to extract meaningful insights and maximize value.Big Data plays a crucial role in applications such as machine learning, predictive modeling, and other advanced analytics, empowering businesses to solve complex challenges and make informed decisions. However, its growing complexity introduces challenges, such as managing vast quantities of real-time data and ensuring data quality. Solutions like Google Cloud’s Data Cloud are aiding organizations in overcoming these challenges by providing scalable infrastructure to unlock the potential of their data. This evolution signifies a paradigm shift in data analytics, where businesses can harness the power of Big Data to gain competitive advantages and drive innovation.
Features and Characteristics of Big Data
A widely recognized framework identifies three core characteristics that define big data: Volume, Velocity, and Variety. These attributes are often referred to as the ”3V model.” Over time, two more characteristics, Veracity and Value, have been incorporated into this framework, providing a more comprehensive understanding of the nature and significance of big data.

3V’s of Big Data
Big Data Analytics in Cloud Computing
Cloud computing has revolutionized the delivery of com- puting services by offering infrastructure, storage, software, and analytics through the internet, commonly referred to as ”the cloud.” This paradigm shift has introduced flexibility,innovation, and cost-efficiency, making it a natural fit for managing and analyzing big data. Businesses benefit from cloud computing’s scalability, pay-as-you-go pricing, and re- duced upfront investment, enabling organizations of all sizes to implement big data projects effectively. Leading cloud providers such as Amazon, Google, and Microsoft offer big data solutions tailored for varying needs, enhancing accessi- bility and efficiency. One emerging concept in this context is Analytics as a Service (AaaS), which simplifies the integration, transformation, and visualization of diverse data types.

Fig. 1. Flow in the processing of Big Data
The big data analytics cycle begins with data gathering from multiple sources, including files, systems, sensors, and web platforms. The collected data is stored in a ”landing zone,” typically a distributed file system capable of handling the volume, velocity, and variety of big data. Once stored, the data undergoes transformations to ensure scalability and efficiency, after which it is integrated into analytical tasks, operational reporting, or databases for further use.A significant shift in big data processing is the transition from the traditional ETL (Extract, Transform, Load) paradigm to ELT (Extract, Load, Transform). ETL processes data transformations on-premises before loading it into a warehouse, which can lead to bottlenecks due to intensive input/output operations and computational demands. In contrast, ELT moves the transformation stage to the cloud, eliminating the need for data staging and enabling the direct ingestion of structured, semi-structured, and unstructured data. ELT leverages ”data lakes,” which do not require prior transformation, providing flexibility and adaptability. Unlike traditional OLAP (Online Analytical Processing) data warehouses, data lakes store raw data, allowing for on-demand transformations specific to analytical needs. This approach minimizes pipeline modifications and facilitates the handling of diverse data formats.
Advantages of Big Data Analytics
Big data analytics offers transformative benefits across industries, empowering organizations to make data-driven
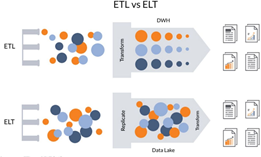
Fig. 2. Differences between ETL and ELT
decisions. Key advantages include:
LITERATURE REVIEW
The document titled ”Big Data with Cloud Computing: Discussions and Challenges” discusses the relationship between big data and cloud computing. It highlights the challenges and issues that arise in processing and storing big data and explores the role of cloud computing in addressing these challenges. The document also provides an overview of various cloud computing platforms and their comparative analysis for storing and managing big data. Additionally, it discusses the research issues in big data, including distributed database storage, data security, heterogeneity, data processing and cleaning, and data visualization. Overall, the document aims to shed light on the intersection of big data and cloud computing and the implications for data storage and analysis.The synergy between big data and cloud computing unfolds a spectrum of advantages crucial for modern organizations. One key benefit is scalability—cloud platforms empower seamless resource scaling, adapting to the ebbs and flows of data processing demands without hefty infrastructure investments. Cost-effectiveness reigns supreme; paying only for utilized resources sidesteps the need for upfront hardware and software expenses. Flexibility thrives within cloud-based solutions, allowing tailored adjustments in storage and processing capabilities as organizational needs evolve. Collaboration blossoms in this intersection, fostering data sharing and teamwork among diverse users and teams, amplifying the efficiency of analytical endeavors. Accessibility becomes universal; these solutions transcend geographical confines, harnessing big data analytics’ potential from any corner tethered to an internet connection. Security, a paramount concern, finds robust fortification within cloud providers’ protective measures, elevating data protection compared to on-premises solutions Performance becomes an ace up the sleeve, courtesy of high-caliber computing prowess within cloud platforms, expediting the processing and analysis of vast datasets. Moreover, integration flourishes; these cloud-based solutions seamlessly meld with other services and tools, effortlessly assimilating into existing systems and workflows.These manifold advantages coalesce to render the convergence of big data and cloud computing a potent force for organizations aiming to harness the true potential of data analytics.The convergence of big data and cloud computing indeed offers incredible advantages, but it’s crucial to acknowledge the associated drawbacks. Firstly, concerns loom over data security and privacy; the vast storage and processing capabilities in the cloud increase the risk of unauthorized access, breaches, and misuse of sensitive information. Additionally, the movement of substantial data volumes between cloud and local systems raises latency issues, potentially impeding real-time analysis and decision- making. While scalability and efficiency are touted benefits, the expenses of long-term storage and complex analytics tasks in the cloud can be steep. Moreover, cloud reliance heavily hinges on internet connectivity, making interruptions detrimental to data access and analytics performance. Data integration poses another hurdle as diverse data formats demand meticulous cleansing, transformation, and compatibility efforts. Organizations embracing a specific cloud provider may face vendor lock-in, hindering flexibility in migration or transitions to other platforms. Furthermore, limited control over underlying infrastructure and security measures in the cloud could raise compliance concerns for industries with stringent regulations. It’s imperative to tackle these challenges by implementing robust security measures, efficient data management strategies, and adherence to compliance standards to ensure the safe and effective utilization of big data within cloud environments.In examining the landscape of big data and cloud computing, several key research gaps come to light, each posing an opportunity for innovation and advancement. Firstly, the realm of distributed database storage beckons for enhanced systems, ones that are not just efficient but also scalable within cloud computing environments. Next, the crucial matter of data privacy and security necessitates cutting-edge algorithms that can effectively safeguard against breaches and unauthorized access. Another avenue ripe for exploration involves devising tools to handle the diverse data formats, enabling seamless integration and analysis across varied data sources. Moreover, delving into real- time data visualization techniques tailored to the swift and varied nature of big data would empower users to glean insights and make timely, informed decisions. Additionally, optimizing load balancing algorithms and resource allocation strategies in cloud setups remains a promising area for further investigation, ensuring optimal utilization of computing resources. Lastly, the exploration of novel data partitioning and sampling methods stands as an essential pursuit to efficiently analyze large-scale data while considering factors like distribution, size, and computational resources. These research gaps serve as gateways to furthering the realms of big data and cloud computing, addressing critical challenges associated with handling, processing, and interpreting vast and diverse datasets.
This paper presents a novel framework for processing large- scale remotely sensed data in cloud computing environments. The proposed approach takes advantage of the parallel processing capabilities of cloud computing and incorporates task scheduling strategies to further exploit parallelism during distributed processing. The framework uses a computation- and data-intensive pan-sharpening method as a study case and develops an optimization framework to minimize total execution time. The paper discusses the decision variables and constraints of the optimization model and proposes a metaheuristic scheduling algorithm based on a quantum- inspired evolutionary algorithm (QEA) to solve the scheduling problem. Experimental results demonstrate that the proposed framework achieves promising speedups as compared with the serial processing approach and is scalable with regard to the increasing scale and dimensionality of remote sensing data. This paper provides a valuable contribution to the field of big data processing and cloud computing, offering a practical solution for processing massive amounts of remote sensing images on cloud computing platforms.The proposed framework for processing remotely sensed big data in cloud computing environments offers several potential benefits. The framework is designed to be scalable, making it a practical solution for processing massive amounts of data. By taking advantage of the parallel processing capabilities of cloud computing and incorporating task scheduling strategies, the framework is able to minimize total execution time and achieve promising speedups as compared with the serial processing approach. The framework uses an optimization model and a metaheuristic scheduling algorithm to determine an optimized solution of task partitioning and task assignments, resulting in high utilization of cloud computing resources and significant speedup for remote sensing data processing. Additionally, the framework uses a computation- and data-intensive pan-sharpening method as a study case, making it a practical solution for processing remote sensing images on cloud computing platforms. Overall, the proposed framework offers a valuable contribution to the field of big data processing and cloud computing, providing a practical and efficient solution for processing large-scale remotely sensed data.Potential considerations and limitations of the proposed framework for processing remotely sensed big data in cloud computing environments should be taken into account. The implementation and management of a distributed computing framework in cloud environments can introduce complexity in terms of system architecture, resource allocation, and maintenance. Efficient utilization of cloud computing resources and optimization of task scheduling may require specialized expertise and a deep understanding of the underlying infrastructure. Additionally, the introduction of a distributed mechanism and task scheduling concept may introduce additional overhead in terms of coordination, communication, and synchronization among computing resources. The effectiveness of the framework may also be contingent on the reliability and performance of the cloud computing platform, potentially introducing vulnerabilities or dependencies. Furthermore, integrating the proposed framework into existing remote sensing data processing workflows or infrastructure may require careful consideration of compatibility, data migration, and potential disruptions during implementation. These potential limitations and considerations should be carefully evaluated to assess the practical implications and trade-offs associated with the adoption of the proposed framework.A potential research gap or area for further investigation could be the evaluation of the proposed framework in comparison to other existing cloud computing solutions for processing remote sensing big data. While the paper provides promising results and demonstrates the effectiveness of the proposed framework in terms of execution time and scalability, it’s important to consider how the framework compares to other approaches in terms of performance, efficiency, and practicality. Additionally, further research could explore the potential limitations and trade-offs associated with the adoption of the proposed framework, such as the complexity of implementation and management, resource requirements, and potential dependencies on cloud infrastructure. By conducting further analysis and evaluation, researchers could gain a deeper understanding of the practical implications and potential benefits of the proposed framework, as well as identify areas for improvement or optimization.
The rapid growth of mobile cloud computing and big data applications has revolutionized service models and application performances, but it has also introduced significant challenges,particularly in the realm of data security. The execution time of data encryption during processing and transmissions has emerged as a critical issue, leading many applications to compromise on data encryption to maintain performance levels, thereby raising privacy concerns. In response to this, the paper focuses on addressing privacy issues and presents a pioneering data encryption approach known as Dynamic Data Encryption Strategy (D2ES). This approach aims to selectively encrypt data and employ privacy classification methods within specified timing constraints, with the goal of maximizing privacy protection while meeting execution time requirements. The paper evaluates the performance of D2ES through experiments, providing evidence of its efficacy in enhancing privacy. With the proliferation of big data in mobile cloud computing, the need for privacy-preserving data encryption strategies becomes increasingly imperative, and this paper seeks to contribute to this vital area of cybersecurity.The Dynamic Data Encryption Strategy (D2ES) approach offers several advantages in addressing the challenges of data security and privacy in mobile cloud computing and big data applications. D2ES allows for selective encryption of data, enabling the maximization of privacy protection while considering timing constraints and performance requirements. By employing privacy classification methods and selective encryption, D2ES enhances privacy levels, addressing the critical issue of privacy concerns in mobile cloud computing and big data applications. The approach is supported by experimental evaluations, providing tangible evidence of its effectiveness in enhancing privacy while maintaining performance levels. D2ES is designed to adapt to the specific timing constraints and execution time requirements, making it suitable for a wide range of applications and scenarios in mobile cloud computing. Overall, the Dynamic Data Encryption Strategy (D2ES) approach offers a promising solution to the challenges of data security and privacy in the context of mobile cloud computing and big data applications, contributing to the crucial area of cybersecurity.Implementation of D2ES may require additional computational resources, which could potentially impact performance. Additionally, the approach may require careful consideration of the specific timing constraints and execution time requirements of each application, which could add complexity to the implementation process. Finally, the effectiveness of D2ES may depend on the specific context and application, and further research may be necessary to evaluate its efficacy in different scenarios.The research gap in the context of the presented paper lies in the need for further exploration and validation of the Dynamic Data Encryption Strategy (D2ES) approach in diverse real- world scenarios and applications. While the paper provides experimental evaluations to support the effectiveness of D2ES, there is a potential research gap in the comprehensive assessment of its performance across a wide range of mobile cloud computing and big data use cases. Additionally, the specific considerations for integrating D2ES into existing systems and architectures, as well as its scalability and adaptability to evolving technological landscapes, could be areas for further investigation. Furthermore, the paper acknowledges the importance of practical measurements in real-world evaluations as a focus for future research, indicating a potential gap in the current understanding of the practical implications and challenges associated with implementing D2ES in complex, dynamic environments. Addressing these research gaps could contribute to a more thorough understanding of the applicability and impact of D2ES in diverse mobile cloud computing and big data contexts.
The main focus of the document is to propose a new approach for virtual machine (VM) placement in a multi data center (DC) cloud environment, specifically for big data applications. The goal is to optimize the placement of VMs in physical machines (PMs) to improve performance, speed, and cost-effectiveness of cloud computing services. The document addresses the challenges of transferring high volumes of traffic between VMs in big data tasks and introduces the aware genetic algorithm first fit (AGAFF) as a context-aware algorithm to minimize traffic between MapReduce nodes.The Aware Genetic Algorithm First Fit (AGAFF) emerges as a pioneering solution in the realm of cloud computing, particularly in the optimization of Virtual Machine (VM) placement for big data applications. Its distinct advantages make it a formidable approach for addressing critical challenges in multi-data center (DC) environments. Notably, AGAFF prioritizes Energy Consumption Reduction by strategically placing VMs, thereby diminishing the number of active servers and consequently lowering overall energy usage. The algorithm also excels in Resource Utilization Maximization by intelligently allocating VMs based on the nuanced usage of CPU and RAM across servers, ensuring optimal utilization of available resources. Furthermore, AGAFF contributes to Reduced Scheduling Time, especially in the context of big data processing, by optimizing VM placement and consequently streamlining task scheduling, leading to enhanced processing speed and overall performance. The algorithm is designed with a keen focus on Service Level Agreement (SLA) Compliance, aiming to minimize violations by ensuring that performance indices are consistently optimized. Additionally, AGAFF addresses the challenge of Minimized Intra-DC Traffic by employing a structured approach to reduce data traffic between MapReduce nodes in big data tasks, thereby enhancing network efficiency. In essence, AGAFF provides a comprehensive and sophisticated methodology for VM placement optimization, offering solutions to key challenges such as energy consumption,resource utilization, scheduling time, SLA compliance, and data traffic management in the dynamic landscape of cloud computing for big data applications.The Aware Genetic Algorithm First Fit (AGAFF) demonstrates notable drawbacks in its application to optimizing virtual machine placement for big data applications in cloud computing. Firstly, its Limited Scope presents a challenge, as AGAFF is tailored specifically for big data tasks and may not be adaptable or suitable for other application types or diverse scenarios. The inherent Complexity of AGAFF, rooted in the computational intensity of genetic algorithms, can result in extended execution times and increased resource utilization, potentially impacting overall efficiency.Moreover, AGAFF faces a significant concern regarding Lack of Scalability, as its performance may suffer with the growing scale of the problem, especially as the number of virtual machines and data centers increases. Dependency on Initial Population is another issue, where AGAFF’s reliance on the first fit (FF) methodology for generating the initial population can introduce variability in performance, heavily influenced by the quality of the initial solutions.In addressing placement solutions, AGAFF’s tendency to select solutions with the lowest cost among feasible options may lead to challenges, particularly in scenarios where all solutions are deemed infeasible due to resource constraints. Additionally, the Lack of Adaptability is a pertinent drawback, as AGAFF may struggle to cope with dynamic environments characterized by frequent changes in resource availability and workload patterns, hindering its ability to efficiently handle real- time adjustments. Furthermore, the algorithm’s Limited Evaluation approach, primarily comparing performance with a restricted set of other algorithms, raises concerns about the comprehensiveness of its assessment. This limitation may hinder a thorough understanding of AGAFF’s effectiveness across diverse scenarios or in comparison with a broader range of algorithms. In conclusion, while AGAFF offers advantages, such as energy consumption reduction and resource utilization, its drawbacks underscore the importance of careful consideration and evaluation when applying it to optimize virtual machine placement for big data applications in cloud computing.The research gap in the document’s discussion on the optimization of virtual machine placement for big data applications in cloud computing is that many existing solutions for Virtual Machine placement do not adequately consider the specific requirements and challenges of big data tasks. Most research in this area focuses on general Virtual Machine placement without taking into account the need for efficient data transfer between Virtual Machine in big data applications. Additionally, some existing solutions make assumptions or constraints that limit their practical applicability. Therefore, there is a need for more practical and efficient approaches that specifically address the optimization of Virtual Machine placement for big data applications in cloud computing.E. CloudFinder: A System for Processing Big Data Workloads on Volunteered Federated Clouds Cloud Finder is a system designed to support the efficient execution of big data workloads on volunteered federated clouds (VFCs). Its purpose is to enable scientists in data- intensive scientific fields to solve complex, data- and compute- intensive problems by leveraging the computational potential of underutilized private clouds. CloudFinder addresses challenges such as heterogeneity and autonomy of member clouds, access control and security, and complex inter-cloud virtual machine scheduling.By utilizing CloudFinder, scientists can run their big data workloads on cloud federations without the need for significant investment in computing and storage capacity. It provides a unified interface that leverages multiple clouds for their resources, allowing researchers to submit their big data code and data with minimal hassle and receive results in a timely manner. CloudFinder optimally selects a topology to execute the program on, making the execution process more efficient and reducing the turnaround time for experimental results.In summary, CloudFinder contributes to the field of big data science by providing a cost-effective approach to solving complex data- and compute-intensive problems. It enables scientists to leverage underutilized private clouds and federated cloud resources, reducing the need for additional computing and storage capacity. CloudFinder simplifies the execution process, optimizes resource allocation, and improves the efficiency of big data workloads.CloudFinder presents a compelling array of advantages for tackling large-scale data tasks across volunteered federated clouds. Its cost-effectiveness is evident through the utilization of otherwise idle computing and storage resources from multiple clouds, eliminating the need for significant upfront investments. Simplifying the deployment process, CloudFinder autonomously manages data and processing distribution, requiring users only to input their programs and data, leaving the rest—handling failed agents and optimizing parameters—to CloudFinder’s expertise. This automated system significantly cuts down on setup time and manual intervention, ensuring time efficiency in delivering experimental results. Scalability is another forte; CloudFinder seamlessly harnesses the pooled resources of federated clouds to handle intricate and sizable big data workloads. Its adaptable nature allows it to navigate different cloud federations, ensuring flexibility tailored to scientists’ varying needs. In essence, CloudFinder empowers scientists to leverage federated clouds, delivering cost-effectiveness, streamlined deployment, time efficiency, scalability, and adaptability in processing extensive big data workloads.Using CloudFinder for big data workloads across volunteered federated clouds carries several potential drawbacks. Firstly, the inherent heterogeneity and autonomy among member clouds pose a challenge. Varying hardware, software setups, and management policies across these clouds make ensuring consistent performance a tough task.Security is another critical concern in such an open infrastructure. Access control becomes intricate, exposing contributors and users to potential threats from others in the federation, demanding robust security mechanisms.Coordinating virtual machine scheduling across multiple clouds adds complexity. Factors like resource over-subscription and hardware disparities contribute to execution time discrepancies, impacting overall performance across different locations.Scaling the system presents its challenges too. Handling the increasing number of clouds and users demands efficient resource allocation and workload distribution, challenging the system’s scalability.Moreover, users have limited control over the infrastructure, relying on contributed resources that might not align with their specific needs or performance expectations. However, with meticulous system design, robust security measures, and performance optimization techniques, these drawbacks can be alleviated to a considerable extent.The realm of processing big data workloads within volunteered federated clouds offers an expansive arena for exploration, brimming with potential research avenues, particularly concerning CloudFinder. Within this domain, several noteworthy research gaps beckon for deeper investigation.Security stands tall as a critical concern within volunteer cloud federations. Delving into the development of robust security mechanisms becomes pivotal, aiming to safeguard the integrity of resources and data for all stakeholders involved, spanning resource contributors to end- users.Scalability surfaces as a multifaceted challenge within open volunteer cloud federations. Unraveling techniques that ensure the scalability of such systems becomes imperative, considering the extensive involvement of numerous organizations and users.Resource management emerges as a linchpin for optimizing the execution of big data workloads. Further research avenues beckon toward the crafting of advanced resource management techniques and algorithms. These innovations must navigate the intricacies of heterogeneity and autonomy present within member clouds within a federated environment.Workload placement assumes a pivotal role within CloudFinder’s ambit. Enhancing workload placement algorithms becomes a promising avenue for future research, aiming to factor in diverse elements like hardware disparities, resource over-subscription, and transfer times. Such considerations strive to culminate in optimal execution times for big data workloads.Interoperability, an ever-pertinent concern, unfurls as a promising frontier for CloudFinder. While currently operating within the GENI cloud federation, bridging interoperability with other federations or even multiple federations emerges as an imperative. Research thrusts towards crafting frameworks and architectures that facilitate seamless integration and interoperability across diverse cloud federations.These distinctive research gaps carve out promising opportunities for further strides and evolution within the domain of processing big data workloads in volunteered federated clouds. Specifically, these areas present a stimulating landscape for advancing the functionalities and scope of CloudFinder, charting new trajectories for innovation and progress in this dynamic field.
CONCLUSION
The convergence of big data and cloud computing offers several advantages, including scalability, cost-effectiveness, flexibility, collaboration, and accessibility. Cloud platforms allow seamless resource scaling, adapting to the demands of data processing without heavy infrastructure investments. Paying only for utilized resources eliminates the need for upfront hardware and software expenses. Cloud-based solu- tions offer flexibility in storage and processing capabilities, allowing tailored adjustments as organizational needs evolve. Collaboration is fostered, enabling data sharing and teamwork among diverse users and teams. Accessibility becomes uni- versal, harnessing the potential of big data analytics from any location with an internet connection. However, there are also challenges associated with the convergence of big data and cloud computing. Data security and privacy are major concerns, as the vast storage and processing capabilities in the cloud increase the risk of unauthorized access and breaches. Latency issues may arise when moving large volumes of data between cloud and local systems, potentially impeding real- time analysis. Long-term storage and complex analytics tasks in the cloud can be expensive. Cloud reliance is dependent on internet connectivity, making interruptions detrimental to data access and analytics performance. Data integration can be challenging due to diverse data formats, requiring meticulous cleansing, transformation, and compatibility efforts. Vendor lock-in may limit flexibility in migration or transitions to other platforms, and limited control over infrastructure and security measures in the cloud may raise compliance concerns.In sum- mary, the convergence of big data and cloud computing offers significant advantages but also presents challenges related to security, latency, cost, data integration, vendor lock-in, and compliance
REFERENCE


Anugraha P. P., Hiba Fathima K. P, Big Data Analytics In Cloud Computing, Int. J. Sci. R. Tech., 2025, 2 (1), 167-175. https://doi.org/10.5281/zenodo.14637762
 10.5281/zenodo.14637762
10.5281/zenodo.14637762
